GPT人工智能运作原理详解:Transformer架构与大规模语料训练
chatgpt原理GPT使用了Transformer这一强大的模型架构。大规模语料训练为了使GPT更聪明,开发者采用了大量的文本资料进行训练。依据这些人工评价,对模型进行调整和提升,让生成的答案更加精确,更贴近人的需求,这就像老师辅导学生不断进步一样。



ChatAI GPT
官方中文版
免费ChatAI 人工智能 GPT 官方中文版
国内访问 | 免费使用 | 极速体验
国内访问 | 稳定性高 | 免费试用 | 极速体验
ChatAI GPT
官方中文版
免费ChatAI 人工智能 GPT 官方中文版
国内访问 | 免费使用 | 极速体验
国内访问 | 稳定性高 | 免费试用 | 极速体验
chatgpt原理GPT使用了Transformer这一强大的模型架构。大规模语料训练为了使GPT更聪明,开发者采用了大量的文本资料进行训练。依据这些人工评价,对模型进行调整和提升,让生成的答案更加精确,更贴近人的需求,这就像老师辅导学生不断进步一样。
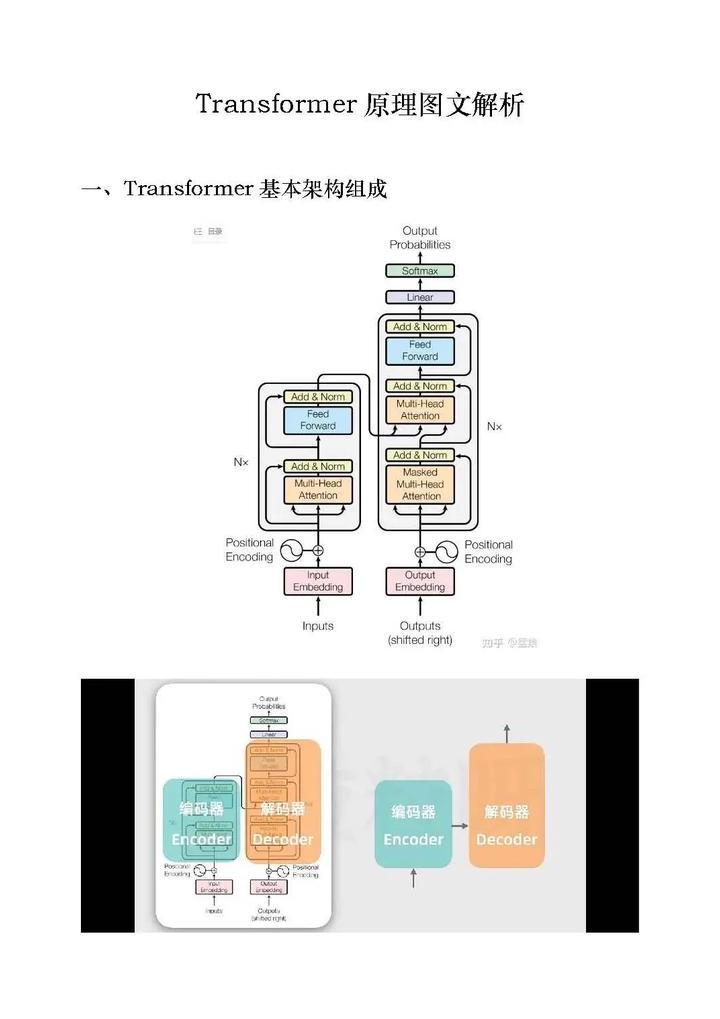
本质上,它是一个依托人工智能技术打造的大规模语言模型。通过学习这些海量文本,GPT掌握了众多概念和语义。处理大量数据,必须运用复杂的算法进行优化。Transformer架构中,存在一种自注意力机制。通过微调,可以增强GPT在特定领域的表现能力。通过改进算法,对模型的各项参数进行细致调整。
它看似神奇,实则背后依托着众多技术原理。这种架构不同于以往循环神经网络按顺序处理数据的方式。预训练是GPT的关键步骤。通过预训练,GPT具备了适应不同类型输入的能力,能够应对各种问题,无论是科学知识还是日常对话。比如,在针对特定领域的问题回答中,微调可以降低答案的偏差。